Mở đầu: Bài toán của Data Engineer trong kỷ nguyên dữ liệu hỗn loạn
Là một Data Engineer, bạn có lẽ đã quá quen thuộc với tình cảnh này: dữ liệu đổ về từ hàng chục nguồn khác nhau—log server, IoT sensors, mạng xã hội, CRM—mỗi loại một định dạng, một cấu trúc. Nỗi đau về dữ liệu không đồng nhất và bài toán quản lý tập trung ngày càng trở nên nhức nhối. Việc lựa chọn sai kiến trúc lưu trữ không chỉ lãng phí tài nguyên mà còn có thể “bóp nghẹt” tiềm năng phân tích và Machine Learning của toàn doanh nghiệp. Câu hỏi đặt ra không còn là “có nên lưu trữ không?” mà là “lưu trữ ở đâu và như thế nào?”. Hai cái tên được nhắc đến nhiều nhất chính là Data Lake và Data Warehouse. Bài viết này sẽ đi sâu phân tích kỹ thuật, giúp bạn không chỉ hiểu rõ sự khác biệt cốt lõi mà còn biết chính xác khi nào nên chọn giải pháp nào để xây dựng kho dữ liệu chuẩn cho tổ chức.
Định nghĩa cốt lõi: Phân biệt Hồ dữ liệu và Kho dữ liệu
Trước khi đi vào so sánh chi tiết, chúng ta cần làm rõ bản chất của hai khái niệm nền tảng này trong một Big Data architecture.
Data Lake (Hồ dữ liệu): Vùng chứa thô, linh hoạt vô hạn
Hãy hình dung Data Lake như một hồ nước tự nhiên khổng lồ. Nó tiếp nhận mọi nguồn nước (dữ liệu) ở định dạng gốc, bất kể là nước mưa (dữ liệu phi cấu trúc như hình ảnh, video), nước suối (dữ liệu bán cấu trúc như JSON, XML) hay nước đã qua xử lý (dữ liệu có cấu trúc từ database). Data Lake không đòi hỏi phải định hình dữ liệu ngay khi đưa vào. Thay vào đó, nó áp dụng cơ chế Schema-on-Read, nghĩa là cấu trúc chỉ được áp dụng khi dữ liệu được đọc ra để phân tích. Đây là sân chơi lý tưởng cho các Data Scientist khám phá và tìm kiếm insight ẩn.
Data Warehouse (Kho dữ liệu): Kho vàng đã được tinh chế
Ngược lại, Data Warehouse giống như một nhà máy đóng chai nước tinh khiết. Chỉ những nguồn nước (dữ liệu) đã được lọc, xử lý và chuẩn hóa thông qua một quy trình nghiêm ngặt (thường là ETL process) mới được đưa vào lưu trữ. Nó sử dụng cơ chế Schema-on-Write, yêu cầu dữ liệu phải tuân theo một cấu trúc được định nghĩa trước. Mục tiêu của kho dữ liệu là phục vụ cho các hoạt động Business Intelligence (BI), báo cáo và truy vấn phân tích với tốc độ cực nhanh, cung cấp một “nguồn chân lý duy nhất” (single source of truth) cho toàn doanh nghiệp.
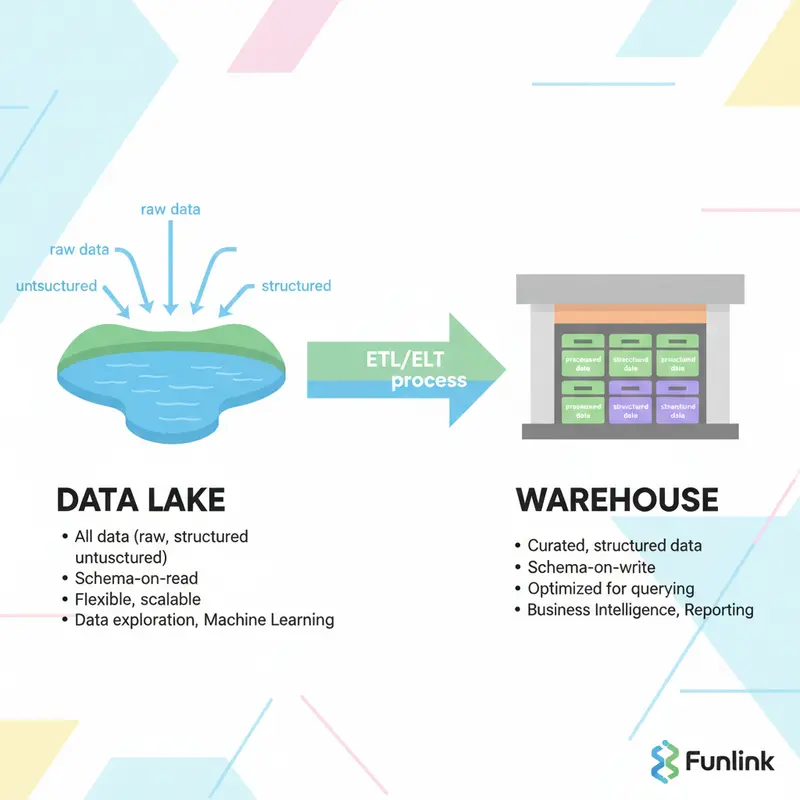
So sánh chi tiết Data Lake vs Data Warehouse trên 8 khía cạnh kỹ thuật
Để giúp bạn có cái nhìn trực diện nhất, hãy đặt hồ dữ liệu và kho dữ liệu lên bàn cân so sánh qua các tiêu chí quan trọng đối với một Data Engineer.
1. Cấu trúc dữ liệu (Data Structure)
- Data Lake: Lưu trữ tất cả các loại dữ liệu: có cấu trúc, bán cấu trúc và phi cấu trúc ở định dạng thô.
- Data Warehouse: Chỉ lưu trữ dữ liệu có cấu trúc, đã được xử lý và định dạng lại.
2. Quy trình xử lý (Data Processing)
- Data Lake: Sử dụng quy trình ELT (Extract – Load – Transform). Dữ liệu được tải vào hồ trước, sau đó mới được chuyển đổi khi cần thiết cho một mục đích phân tích cụ thể.
- Data Warehouse: Sử dụng quy trình ETL (Extract – Transform – Load) truyền thống. Dữ liệu phải được làm sạch, chuyển đổi trước khi được nạp vào kho.
3. Schema (Lược đồ dữ liệu)
- Data Lake: Schema-on-Read. Linh hoạt, không cần định nghĩa schema trước.
- Data Warehouse: Schema-on-Write. Nghiêm ngặt, schema phải được thiết kế và định nghĩa trước khi nạp dữ liệu.
4. Tốc độ truy vấn (Query Speed)
- Data Lake: Tốc độ truy vấn thường chậm hơn do dữ liệu thô, chưa được tối ưu hóa và cần được xử lý tại thời điểm truy vấn.
- Data Warehouse: Tốc độ truy vấn rất nhanh, được tối ưu hóa cho các hoạt động phân tích và báo cáo BI.
5. Người dùng cuối (End Users)
- Data Lake: Chủ yếu là Data Scientists, Data Analysts có kỹ năng lập trình cao, cần khám phá dữ liệu thô.
- Data Warehouse: Chủ yếu là Business Analysts, nhà quản lý, những người cần các báo cáo và dashboard đã được chuẩn hóa.
6. Chi phí lưu trữ (Storage Cost)
- Data Lake: Chi phí lưu trữ thấp do sử dụng các công nghệ lưu trữ hàng hóa (commodity storage) như Hadoop HDFS hoặc các dịch vụ object storage trên cloud (Amazon S3, Azure Blob Storage).
- Data Warehouse: Chi phí lưu trữ cao hơn đáng kể do yêu cầu hệ thống lưu trữ hiệu năng cao và phức tạp.
7. Tính linh hoạt và khả năng mở rộng (Agility & Scalability)
- Data Lake: Rất linh hoạt và dễ dàng mở rộng. Việc thêm nguồn dữ liệu mới rất đơn giản.
- Data Warehouse: Kém linh hoạt hơn. Việc thay đổi cấu trúc hoặc thêm dữ liệu mới đòi hỏi nhiều nỗ lực trong quy trình ETL.
8. Các trường hợp sử dụng điển hình (Use Cases)
- Data Lake: Phân tích dữ liệu lớn, Machine Learning, Real-time analytics, Data exploration.
- Data Warehouse: Báo cáo quản trị (BI Reporting), Phân tích hiệu quả kinh doanh, SQL analytics.

Kiến trúc Big Data hiện đại: Lựa chọn nào cho bạn?
Việc lựa chọn không phải lúc nào cũng là “hoặc là”. Trong các kiến trúc hiện đại, Data Lake và Data Warehouse thường bổ trợ cho nhau. Tuy nhiên, quyết định ban đầu phụ thuộc vào mục tiêu cốt lõi của bạn.
Chọn Data Warehouse khi…
Bạn cần một nguồn dữ liệu đáng tin cậy cho việc báo cáo BI, khi các câu hỏi kinh doanh đã được xác định rõ ràng và bạn cần câu trả lời nhanh, chính xác dựa trên dữ liệu có cấu trúc (ví dụ: doanh thu theo quý, hiệu suất chiến dịch marketing).
Chọn Data Lake khi…
Tổ chức của bạn muốn khai phá tiềm năng từ dữ liệu phi cấu trúc, xây dựng các mô hình Machine Learning phức tạp, hoặc khi bạn chưa biết trước những câu hỏi mình sẽ hỏi. Data Lake cho phép bạn lưu trữ tất cả và phân tích sau.
Xu hướng kết hợp: Kiến trúc Lakehouse với Databricks và Snowflake
Các công nghệ hiện đại đã xóa nhòa ranh giới. Kiến trúc “Lakehouse” đang nổi lên như một giải pháp tối ưu, kết hợp sự linh hoạt, chi phí thấp của Data Lake với các tính năng quản lý và hiệu năng của Data Warehouse.
- Databricks: Xây dựng trên nền tảng Apache Spark, cung cấp một platform hợp nhất cho cả data engineering, data science và BI trực tiếp trên Data Lake.
- Snowflake: Mặc dù khởi đầu là một Cloud Data Warehouse, Snowflake đã phát triển các tính năng để có thể truy vấn trực tiếp dữ liệu trên các Data Lake bên ngoài, mang lại sự linh hoạt đáng kể.
Cách tiếp cận này cho phép bạn có được những lợi ích tốt nhất của cả hai thế giới.
Tối ưu hóa hạ tầng dữ liệu với Chiến lược Multi-cloud
Trong bối cảnh các nhà cung cấp cloud như AWS, Google Cloud, Azure đều cung cấp các giải pháp mạnh mẽ cho cả Data Lake và Data Warehouse, việc phụ thuộc vào một nhà cung cấp duy nhất có thể tạo ra rủi ro. Một Chiến lược Multi-cloud thông minh giúp bạn tận dụng những công nghệ tốt nhất từ mỗi nhà cung cấp, tối ưu hóa chi phí và đảm bảo tính liên tục của hệ thống dữ liệu. Việc tích hợp các giải pháp như Snowflake hay Databricks trên nhiều nền tảng cloud là một ví dụ điển hình cho xu hướng này.
Kết luận: Xây dựng nền tảng dữ liệu vững chắc cho tương lai
Cuộc đối đầu Data Lake vs Data Warehouse không có người chiến thắng tuyệt đối. Lựa chọn đúng đắn phụ thuộc vào bài toán, người dùng và mục tiêu chiến lược của bạn. Data Warehouse là pháo đài vững chắc cho BI, trong khi Data Lake là đại dương bao la cho khám phá và AI. Kiến trúc Lakehouse hiện đại đang mở ra một chương mới, hứa hẹn một tương lai nơi dữ liệu vừa linh hoạt, vừa có cấu trúc và dễ dàng truy cập.
Hành động ngay: Đừng để dữ liệu hỗn loạn cản bước đổi mới của bạn. Hãy bắt đầu bằng việc kiểm kê lại các nguồn dữ liệu hiện tại, xác định các trường hợp sử dụng ưu tiên và phác thảo một kiến trúc dữ liệu phù hợp. Nếu bạn đã sẵn sàng thiết kế và triển khai một nền tảng dữ liệu hiện đại, có khả năng mở rộng và thực sự giải quyết được bài toán kinh doanh, hãy liên hệ với đội ngũ chuyên gia của chúng tôi để được tư vấn lộ trình chi tiết.